
Mastering ID Generation in Distributed Systems
From UUIDs to Twitter’s Snowflake: A Deep Dive


In working with distributed systems, it is essential to identify various resources such as database records, servers, files, or people. To avoid confusion, we must generate unique IDs for each resource.
Nonetheless, due to the nature of distributed systems, generating unique IDs for each resource is not a trivial task, as there may be collisions depending on the technique employed.
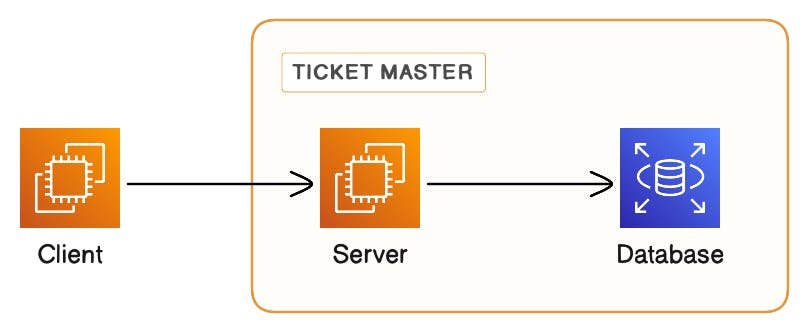
#1: Centralized server/Ticket Master
A centralized server or node can utilize an auto-increment function in a database or employ more intricate logic to distribute IDs to requesting servers. The central node is responsible for ensuring the uniqueness of each generated ID.
Pros:
Most traditional databases support auto-incrementing fields and can be utilized to serve as a ticket master.
As the fields are incrementally generated, it becomes easy to monitor the sequence of resources being tracked.
Cons:
As a ticket master, it serves as a central resource but may struggle with horizontal scalability, leading to latency in the ID generation process during traffic surges and posing a single point of failure risk.
Each instance of ID generation requires a round trip, leading to increased network overhead. This problem greatly impacts nodes that are geographically distant from the central server.
Making it work:
As this is a very simple strategy, it could be rolled out for a system that might not grow in complexity
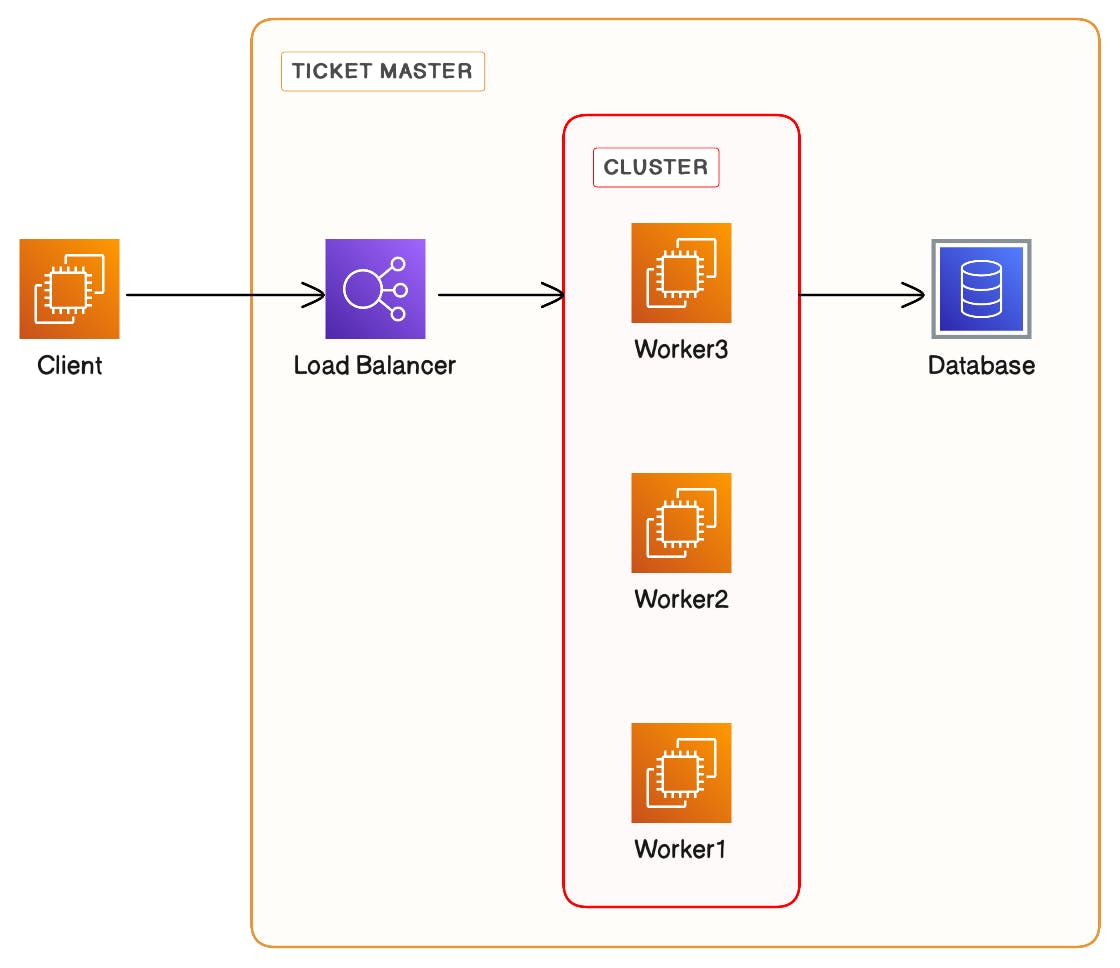
We could implement the ticket master as a cluster of nodes with shared storage. A load balancer to distribute the traffic across the cluster which coordinates before issuing an ID.
Instead of sharing a single ID, a batch of IDs could be shared with the requesting server. However, this would mean that the resources are no longer sequentially organized as per the incrementing IDs.
#2 UUIDs (Universally Unique Identifier)
A UUID is a 128-bit unique identifier. It is represented as a 32-digit hexadecimal number divided into five groups, separated by hyphens, resulting in a 36-character string. An example of a UUID is 2b0a3fd4-a8f0-4b9b-a5e3-dd9c6ae5f72d.
The primary advantage of a UUID is its size: at 128 bits, it can provide up to 3.4 x 10^38 unique values, ensuring an exceedingly low likelihood of duplication even in large datasets and distributed systems.
Pros:
Generating UUIDs does not require any coordination among nodes.
The nodes can directly perform essential actions, such as writing to a database, without the overhead of requesting a unique ID from another node.
UUID generation can be performed offline on the client side, with an extremely low probability of conflicts arising.
Cons:
UUIDs are relatively large, requiring 128 bits or 16 bytes for storage, compared to an auto-incremented ID that might only need 4 or 8 bytes. This difference accumulates as the scale of the data increases.
Databases are optimized for retrieval using indexes. Since UUID v4 is essentially random, it necessitates constant reorganization of the database's index structure. This results in index fragmentation and decreased performance.
UUIDs aren't very readable and can be difficult to work with while debugging.
"The probability to find a duplicate within 103 trillion version-4 UUIDs is one in a billion", which is nearly negligible, but not entirely impossible.
Making it work:
Use UUID v4, as it is random and doesn't have the privacy concerns of v1, which embeds the MAC address of the generating system and can be traced back. However, be aware that randomness contributes to other issues, such as index fragmentation. To address index fragmentation, consider regularly defragmenting indices.
Some databases allow you to store UUIDs in a binary format, which makes it more space-efficient.
Utilize databases optimized for non-sequential keys and random-access workloads. These databases typically belong to the NoSQL category. Popular examples include MongoDB, Cassandra, DynamoDB, and HBase.
#3: Zookeeper's Unique ID Generation
ZooKeeper is a distributed coordination service designed to work with a large cluster of nodes. For unique ID generation, ZooKeeper utilizes a mechanism called "sequential znodes." A znode is a data node, similar to a directory in a file system, and znodes are organized in a hierarchical path structure.
When an application requires a unique ID, it must specify a znode path, such as /app/id- or app/datacenter1/node1/id-. ZooKeeper then generates an ID like /app/id-0000000001. Subsequent requests will produce IDs like /app/id-0000000002 and so forth. ZooKeeper manages the counter and provides a unique sequential ID.
Pros:
By utilizing a quorum-based approach, ZooKeeper prevents a single point of failure. Rather than depending on a single node, ZooKeeper functions on a cluster of machines, referred to as an ensemble. To successfully generate an ID, a majority consensus is necessary.
The mechanism is quite simple. The client merely needs to create a znode path, and ZooKeeper takes care of the rest.
Cons:
The ID generation process introduces latency in the form of a round trip to the ZooKeeper ensemble. This is particularly noticeable for clients that are geographically distant from the ZooKeeper ensemble.
The number of children or IDs a znode can accommodate is substantial but finite. This constraint may pose limitations for specific applications.
Operating and managing a ZooKeeper ensemble requires meticulous operational expertise, especially when dealing with large clusters.
Making it work:
- If a system already utilizes ZooKeeper for other coordination tasks, then employing it for ID generation may be the logical choice.
#4: Twitter's Snowflake method
Twitter encountered challenges when generating unique IDs at a large scale. They also had specific requirements for IDs, such as generating thousands per second, being sorted approximately by creation time, fitting within 64 bits, and not requiring coordination during their generation. To address this issue, Twitter's engineering team developed the Snowflake method.
Generating a Snowflake ID:
Parameters:
Custom Epoch:
January 1, 2023, 00:00:00 UTCCurrent Time:
August 5, 2023, 00:00:00 UTC(assuming today's date)Machine ID:
239
Let's compute the difference between the current time and our custom epoch.
August 5, 2023, 00:00:00 UTC - January 1, 2023, 00:00:00 UTC = 217 days = 18,764,800,000 milliseconds
Representing this value in a 41-bit binary format.
Timestamp (41 bits): 00001001000101000100111011000000000
Machine ID (10 bits): The binary representation of 239 is:
0011101111
Sequence Number (12 bits): Let's assume the first request in that millisecond, so the sequence number is 0:
000000000000
Concatenate these values:
Snowflake ID: 000010010001010001001110110000000000011101111000000000000
Deciphering the ID Components
Timestamp (41 bits):
Purpose: Imposing time-sequentiality ensures a natural order for IDs by leveraging the inherent forward progression of time.
Benefit: Time-based ordering enhances database operations, especially indexing and retrieval, while also allowing the system to function for nearly seven decades.
Our Value:
00001001000101000100111011000000000encapsulates the milliseconds since our specified epoch.Limitation:
Duration: With 41 bits dedicated to the timestamp, the system can theoretically accommodate 2^41 milliseconds, which is approximately 69 years. After this timeframe, the system would exhaust its timestamp capacity, risking ID collision.
Solution: By choosing a suitable custom epoch (such as a significant date for the company or product launch), one can ensure that the 69-year window is used optimally.
Machine ID (10 bits):
Purpose: This fragment ensures that a large number of machines, working concurrently, can independently generate unique IDs, eliminating the risk of collision.
Benefit: This architecture supports decentralization and concurrency. Each device operates independently, distributing the ID generation process.
Our Value: The binary representation
0011101111corresponds to our designated machine with an ID239.Limitation:
Capacity: A 10-bit machine ID can represent 2^10, or 1,024 unique machines. This means the system can only scale to 1,024 machines. Any requirement beyond this would require a design change.
Solution: A larger bit allocation should be considered during the initial design phase if scalability beyond 1,024 machines is anticipated.
Sequence Number (12 bits):
Purpose: The sequence number allows for unique ID creation on a single machine within the same millisecond.
Benefit: The design choice enhances throughput by ensuring distinct IDs for multiple requests within a single millisecond.
Our Value:
000000000000signifies the first ID generated within that millisecond.Limitation:
Throughput: With 12 bits allocated, up to 2^12 or 4,096 unique IDs can be generated per millisecond per machine. For hyper-scale applications or systems with exceptionally high requests per millisecond, this could be a limiting factor.
Solution: The 12-bit allocation allows generating up to 4,096 unique IDs per millisecond per machine, which is sufficient for most applications, but for higher throughput, consider increasing the bit allocation for the sequence number during system design.
Pros:
The decentralized approach eliminates the need for locks or synchronization across machines.
It can generate a massive number of IDs due to its non-blocking nature.
The IDs are inherently ordered, which is advantageous for database indexing and retrieval.
Cons:
If a machine's clock goes backward, there is a risk of ID collision.
The limited size of each component enables the timestamp to operate for roughly 69 years, accommodating up to 1024 machines and producing up to 4096 IDs per millisecond. However, each component can be adjusted according to individual needs.
Making it work:
Use an epoch time that closely aligns with the product launch.
Each participating machine must possess a unique ID.
Implement safeguards to address situations where a machine's clock drifts backward.
Monitor each limiting factor to catch issues early and make the necessary course corrections.
Each of the approaches described for generating unique IDs has its own advantages and disadvantages. Based on the trade-offs and requirements, you can select the one that best fits your design.